
Florent Destremau
CTO fullstack en PHP et JS, je mets les mains dans le code pour accélérer vos projets.
Retrouvez-moi sur LinkedIn,
sur X.com ou consultez mon
Github.
Modèles IA open source : le nouveau marché de l'inférence
Ce qu'on paye vraiment quand on souscrit à un abonnement IA
Quand je paye mon abonnement Claude Max, je paye en réalité trois choses : l'entraînement du modèle, le paywall qui me donne accès à un modèle fermé dont Anthropic détient seul les poids, et l'inférence que je consomme. Conséquence directe : un seul fournisseur possible, et un forfait qui fonctionne largement à perte aujourd'hui. Anthropic et OpenAI brûlent du cash pour conquérir le marché et on voit régulièrement la pression remonter sous forme de quotas réduits, de limites hebdomadaires, d'exclusion de cas d'utilisation comme plus récemment. Le forfait fixe est confortable, mais il masque le coût réel des requêtes ; le jour où la politique tarifaire se durcira, ça va piquer très fort.
L'avantage que je retrouve quand j'utilise opencode avec Kimi 2.6 via Fireworks AI (combo que j'ai découvert en suivant les expérimentations de DHH sur le sujet), c'est que j'ai un compteur de prix en direct sous les yeux. Une tâche m'a coûté 2 €, c'est marqué noir sur blanc. Du coup je peux raisonner en ROI : ce que je viens de faire, est-ce que ça valait 2 € ? Et je peux anticiper le scaling : si je multiplie cet usage par dix dans mon équipe, je sais que ça fera 20 €. Avec un forfait fixe, cette projection est beaucoup plus dure à faire à cause du manque de lisibilité par tâche.
L'open source change l'équation
Avec un modèle open source, qu'il s'agisse de Kimi 2.6, Qwen, Llama, DeepSeek ou GLM, deux des trois composantes disparaissent de mon côté. Le coût d'entraînement est sorti de l'équation pour moi : pas parce qu'il n'existe pas (Moonshot, Alibaba, Meta, DeepSeek ont bel et bien dépensé des sommes considérables pour entraîner ces modèles), mais parce qu'ils ont choisi de publier les poids. Du même coup, le paywall tombe : les poids sont publics, plus personne ne peut me les facturer comme un produit exclusif.
Reste l'inférence. Et l'inférence, ça n'est jamais que du calcul. Des GPU, de la RAM, du réseau, et un du software pour servir le modèle efficacement. C'est-à-dire un problème opérationnel, pas un problème de capital intensif. Le résultat est mécanique : les prix d'inférence sur ces modèles sont systématiquement plus bas que sur les modèles propriétaires de catégorie équivalente, parce qu'il n'y a pas un amortissement de R&D à recouvrer dans chaque token vendu.
Mais ce n'est pas vraiment ça l'important. Le vrai changement, c'est que ça ouvre la concurrence.
Conséquence 1 : n'importe qui peut devenir fournisseur d'inférence
Quand le modèle est public, plus rien n'empêche n'importe quelle entreprise avec un data center de proposer de l'inférence sur ce modèle. Les poids sont là, ils sont stables, ils sont les mêmes pour tout le monde. La seule chose qui différencie un fournisseur d'un autre, c'est la qualité de son infrastructure : latence, débit, prix, disponibilité géographique, conformité, support.
C'est exactement ce qui se passe aujourd'hui. Fireworks AI, Together AI, Groq, DeepInfra, Cerebras, Lambda, OpenRouter qui agrège tout ça... Il y a un véritable marché secondaire de l'inférence en train d'émerger, où la matière première (le modèle) est commune et où la valeur ajoutée se joue sur l'opérationnel. C'est sain : on retrouve une dynamique de marché classique, là où les modèles propriétaires créent un monopole de fait sur leur propre modèle.
Pour quelqu'un qui veut monter une boîte aujourd'hui dans l'IA sans pouvoir aligner les milliards d'Anthropic ou d'OpenAI, devenir un fournisseur d'inférence sur des modèles open source est devenu une voie crédible. Il « suffit », entre gros guillemets, d'un data center et d'un bon stack de serving. Ce n'est pas trivial, mais c'est mille fois plus accessible que d'entraîner un modèle de pointe.
Apparté, le faire tourner chez soi n'est pas vraiment une option à cette échelle : Kimi 2.6 c'est 1T paramètres, ~500 Go de VRAM minimum, donc très loin d'un poste de travail à avoir chez soi. C'est rigolo sur des modèles plus petits (Llama, Qwen 7B), mais sur la classe qui veut rivaliser avec Claude, on passe forcément par un fournisseur d'infra. Ce qui change avec l'open source, ce n'est pas que je vais le faire tourner moi-même : c'est que j'ai le choix du fournisseur.
Conséquence 2 : on peut choisir sa vitesse
Et c'est là que ça devient vraiment intéressant pour l'utilisateur final. Comme plusieurs fournisseurs servent le même modèle, ils peuvent se différencier sur des axes que les éditeurs propriétaires ne proposent pas, notamment la vitesse d'inférence.
Reprenons l'exemple de Fireworks. Pour Kimi 2.6, ils proposent deux modes pour le même modèle :
- un mode standard, à un prix donné, à une vitesse donnée ;
- un mode turbo, environ deux fois plus cher, mais environ deux fois plus rapide.
Le modèle est strictement le même, ce qui change, c'est l'infrastructure dédiée derrière : plus de GPU, du batching plus agressif, des optimisations en tous genres...et ça donne un cadran que je n'avais jamais eu avant en IA : un curseur prix / vitesse, à qualité de réponse constante.
En pratique, ça change ma manière de bosser. Pour un long refacto où l'agent va tourner pendant 20 minutes en arrière-plan, je reste en standard : je n'ai pas besoin que ça aille plus vite, et ça me coûte moitié moins cher. Pour une tâche critique où j'attends activement devant l'écran, où chaque minute compte parce que je suis en train de débugger un truc qui bloque, je passe en turbo et j'accepte de payer le double. Le surcoût s'arbitre par rapport au temps de cerveau que je gagne.
Une nuance importante : on a besoin des deux camps
Ce serait malhonnête de présenter ça comme un match où les labs propriétaires seraient les méchants. Sans la course en tête menée par Anthropic, OpenAI ou Google, l'open source aurait beaucoup moins à reproduire et à distiller. Et l'écart se réduit vite : selon le Capabilities Index d'Epoch AI, les modèles ouverts n'ont plus que ~4 mois de retard sur les modèles fermés.
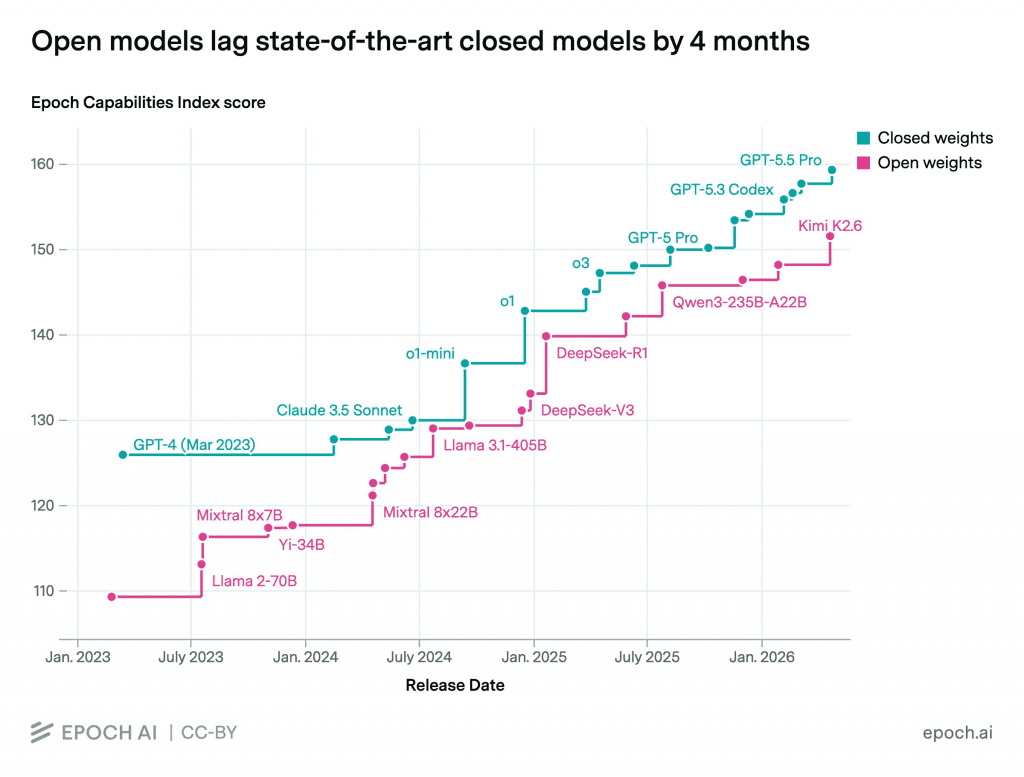
Revers de la médaille : il faut aussi se méfier de l'équilibre économique des publieurs de modèles ouverts. Moonshot, Mistral, DeepSeek, Meta sur sa division IA, tous doivent trouver un modèle d'affaires viable. Publier les poids gratuitement, c'est un cadeau colossal à l'écosystème, mais c'est très dur à monétiser. Si on veut que le robinet reste ouvert, on a un intérêt collectif à ce que ces boîtes survivent.
En résumé
Payer Claude, c'est payer un éditeur intégré verticalement qui contrôle R&D, paywall et infra de bout en bout. Payer Fireworks (ou Together, ou Groq) pour faire tourner Kimi 2.6, c'est payer un service d'infrastructure sur une matière première commune. Le rapport de force n'est pas le même, et même à qualité de modèle équivalente, l'open source offre des libertés que le fermé ne peut structurellement pas offrir : choix du fournisseur, modulation prix/vitesse, juridiction d'hébergement, pérennité dans le temps.
Pour autant, les deux camps se nourrissent l'un de l'autre. Sans les labs propriétaires qui tirent l'état de l'art, l'open source aurait beaucoup moins à reproduire ; sans la pression de l'open source, les abonnements fermés ne sentiraient aucune urgence à ajuster leurs prix ou leurs quotas. Pour la majorité des usages où la qualité de l'open source est désormais suffisante, le ratio coût / contrôle penche clairement du côté ouvert. Pour le reste, les labs propriétaires gardent l'avantage, et c'est tant mieux qu'ils continuent à pousser. Le vrai changement, c'est qu'on a maintenant le choix de l'arbitrage à faire.